Dr. Sárközy Ferenc: Térinformatika
Thursday, June 24, 1999
Néhány kvázi szabványos illetve szabványos
információtechnológiai eszköz I
Ezen a lapon
Ebben a részben néhány adósságunkat törlesztjük, illetve
néhány olyan eszközzel ismerkedünk meg, melyekre a következő alpontokban az
Open GIS koncepció, a magyar térbeli adatátviteli szabvány és a WEB GIS
ismertetésekor lesz szükségünk.
Tulajdonképpen azt is írhattuk volna, hogy kibővítjük
ismereteinket az 1. fejezetben megismert adatleíró nyelvekről (DDL), ez azonban
nem fedi teljesen a fejezet tartalmát. Az egyik adatleíró nyelvvel (EXPRESS)
kapcsolatban ugyanis ha csak röviden is, de utalnunk kell a STEP nevű
nemzetközi mérnöki termék szabványra, két másik leíró nyelv (UML, IDL) illetve
maga az Open GIS koncepció igényli, hogy a CORBA rendszer példáján bemutassuk
az úgynevezett midleware hálózati szoftver rendszerek lényegét.
Előre kell bocsátanunk, hogy ezeket az ambiciózus terveket
csak magas fokú generalizálással, azaz csak eléggé felületesen lehet megvalósítani
egy alponton belül. Ezért az érdeklődő olvasóknak megadjuk azokat az irodalmi
esetleg Internet címeket, ahol a témáknak utána olvashatnak.
Hálózati és relációs adatmodellező módszerek: az
Objektum-Kapcsolat (Entity-Relationship), röviden ER diagrammok és az IDEF1x
modellező nyelv
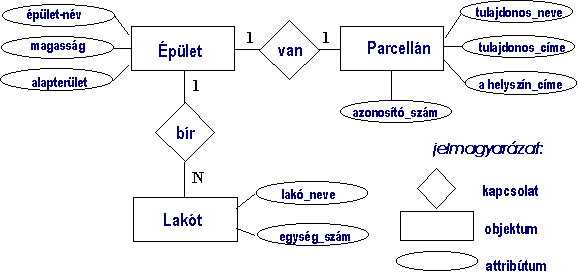
Az ER diagrammok a korszerű adatbázis-kezelő
rendszerek kialakulásával, a modellezési igények megjelenésével jöttek létre.
Feladatuk az volt, hogy áttekinthető grafikus eszközökkel megkönnyítsék az
adatbázisok logikai tervezését. Az eredeti formájában az ER diagramm
entitásokat, hozzájuk tartozó attribútumokat és kapcsolatokat tartalmazott
abban a formában, ahogyan ezt az 5.35 ábrán látjuk.
|
|
5.35 ábra -
egyszerű ER diagram
|
A kapcsolat típusok az alábbiak lehetnek:
- tartozik
valamihez;
- halmaz
és részhalmaz kapcsolatok;
- szülő
- gyermek kapcsolat;
- objektum
részei.
Eredmény a formálisan specifikált entitások, attribútumaik,
kapcsolataik, a kapcsolatok esetében fontos a kapcsolat jellege (1:1, 1:N,
N:M), melyet az ábrán a kapcsolatot reprezentáló vonal mellett tüntettünk fel.
A földrajzi adatok esetében a fizikai objektum meghatározásnak
(ház) mindég absztrakt térbeli objektum meghatározás (poligon) felel meg.
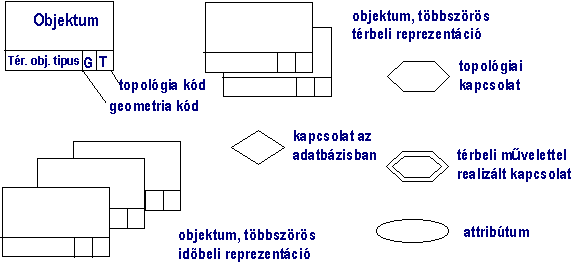
A térbeli adatok esetére, újabban kiegészítő
jelöléseket alkalmaznak az 5.36 ábrán bemutatott módon:
Az új jelölések lehetővé teszik a térbeli objektumok és
kapcsolatok ábrázolását. Érdekes megfigyelni az objektumok kiterjesztett
formalizmusát (típus, geometriai kód, topológiai kód) illetve a térben vagy
időben többszörös objektumok jelölését. A térben többszörös objektum azt
jelenti, hogy különböző méretarányban más geometriai objektum is ábrázolhatja
ugyanazt a fizikai objektumot, pld. kis méretarányban az utat vonal ábrázolja,
míg nagy méretarányban poligon.
|
|
5.36 ábra - az
ER diagram térbeli kiterjesztése
|
|
|
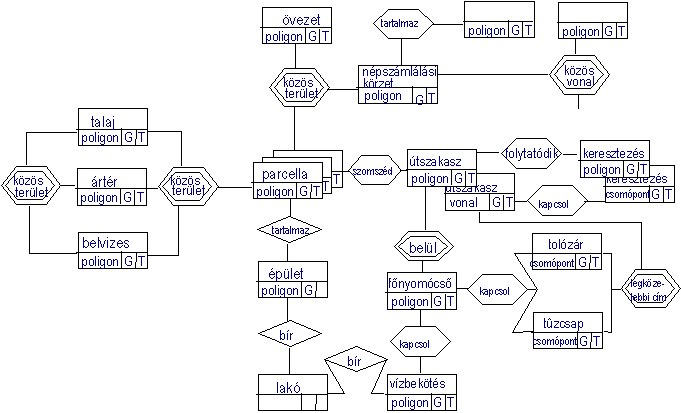
A térbeli kitérőnk alkalmazásának illusztrálására nézzünk meg
egy részletet egy város térbeli adatbázisának ER diagramjából (5.37 ábra).
|
|
5.37 ábra -
részlet egy városi rendszer ER diagramjából
|
Az ER diagramok a hálós adatbázis koncepciónak köszönhették
létrejöttüket és az adatbázis létrehozásának vizuális segítésére szolgáltak. A
programozó a diagrammok szemlélésével könnyebben tudta a kérdéses
adatbázis-kezelő szoftver DDL-jében programozni a gazda és tag rekordokat.
Az idő múlásával azonban a relációs adatbázis
kezelők fokozatosan kiszorították a hálózati modellt és az ER diagramokat
relációk létrehozására kezdték használni. Ez elvileg lehetséges, hiszen a
relációs adatbázis-kezelők kezdetben a programozást megkönnyítő interfészek
voltak a hálózati modellű adatbázis-kezelő rendszereken.
Ez a megoldás azonban nem volt tökéletes
részben azért, mert az ER nem támogatta közvetlenül a relációs adatmodellt,
részben pedig azért mivel a finomabb részletekben (elnevezések, megírási
szabályok, részdiagramok összekapcsolása, stb.) számtalan szokás alakult ki,
mely egyrészt megnehezítette a diagramok portabilitását, másrészt, és ez a
fontosabb, megnehezítette az ER módszer alkalmazását a logikai adatbázis séma
automatizálásra.
A korai 80-as években ugyanis megkezdődött a programozás
automatizálását támogató programok az úgynevezett CASE (Computer Aided
Software and Systems Engineering), azaz magyarul Automatizált
Szoftver és Rendszer Készítő eszközök elterjedése, melyek egy csoportja
aktívan támogatja az adatbázisok létrehozását diagram rajzolással
(koncepcionális tervezés), és a diagramok alapján kódgenerálással (logikai
tervezés).
Az automatizálás alatt a relációs adatbázisok esetén tehát azt
kell érteni, hogy a diagramot típus elemekből a számítógépen építik fel,
kitöltve szabványos formátumú elnevezésekkel az elemek írható részét, majd a
kész diagramot a gép automatikusan SQL szkriptre fordítja, mely alkalmazva
valamely relációs adatbázis-kezelőre létrehozza a diagramban definiált
táblázatokat, hasonlóan ahhoz, ahogy ezt a TSSDS SQL generátora csinálta.
A célból hogy a relációs adatbázis tervezés
egész folyamatát konzisztenssé és szabványossá tegyék az amerikai Légierő
létrehozta az IDEF1X modellező módszert, melyet az amerikai szabványügyi és
technológiai intézet (NIST) 1993-ban föderális informatikai szabványként
publikált [6].
Mielőtt felvázolnánk az IDEF1X néhány jellemzőjét két dolgot
elöljáróban el kell mondanunk. Az első az, hogy a viszonylag részletesen
bemutatott TSSDS szabvány (illetve szabványos adatbázis) is az IDEF1X
felhasználásával készült, már csak azért is, mivel az USA Védelmi Minisztériuma
rendeletileg előírta kötelező használatát minden minisztériumi kompetenciájú
informatikai tervezésre, a második megjegyzésünk pedig arra vonatkozik, hogy a Knowledge Based Systems, Inc. (KBSI) cég által
kifejlesztett SmartER automatizálja a módszerrel tervezett adatbázis
létrehozását.
Az IDEF1X módszert direkt a relációs adatbázis
koncepcionális tervezésre hozták létre.
Egyik alapkoncepciója, hogy egy doboz a hasonló objektumok
együttesét tartalmazza, mely objektumok mindegyikéhez attribútum csatlakozik,
melyet a dobozba írt attribútum név képvisel. Minden, az egyedek közötti
relációnak neve van, ami biztosítja az integritást. A relációkat a dobozok
összekötő vonala jellemzi.
A rendszer támogatja a logikai
adatstruktúrákat megkönnyítve ezzel az adatok csoportosítását és
rendszerezését.
Az IDEF1X modell három színtű
grafikából, szójegyzetből és modell megjegyzésekből áll.
Az elnevezések formáját lexikális konvenciók korlátozzák. A grafika lehet
- ER színtű, melyben nem szerepelnek a kulcsok;
- Kulcs
alapú (KB), melyben megjelenik a különbség a
független és függő objektumok között és meghatározott szabályok szerint
beírásra kerülnek az elsődleges és másodlagos kulcsok, az M:N relációk 1:N
relációkká átalakítva jelennek meg;
- Teljes
attribútumú (FA), melyben az előző pontban
leírtak mellett az összes fontos attribútumot feltüntetik az objektumok
dobozában.
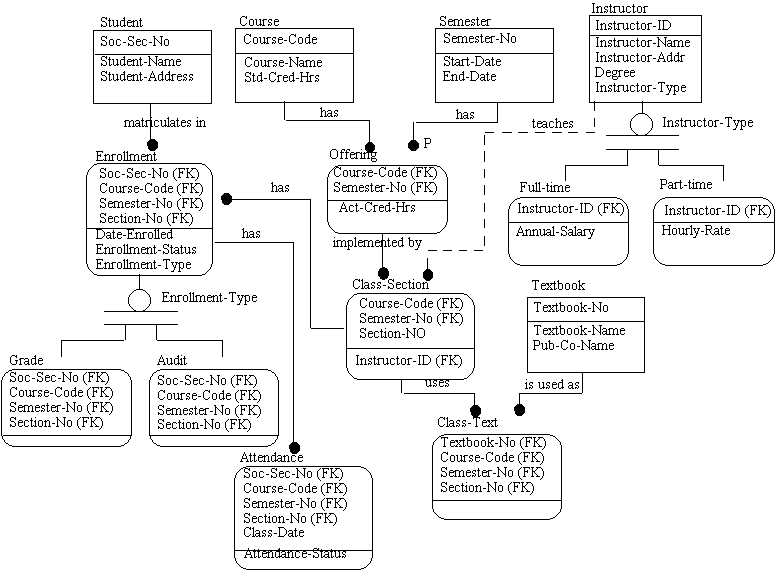
A szabvány egyszerű és gyors összefoglalását talán az segíti a
legjobban, ha megnézünk egy FA színtű diagram példát a szabványból (5.38
ábra) és ezzel kapcsolatban mutatjuk be a legfontosabb tartalmi és jelölési
kérdéseket. Megjegyzendő, hogy ha pld. a SmartER program segítségével a magyar
elnevezésekkel próbáljuk megszerkeszteni a modellt, úgy az ékezetes betűket
kerülnünk kell.
Az ábra felső sorában négy téglalapot látunk, fölöttük egy-egy
névvel (Student=Diák, Course=Tantárgy, Semester=Szemeszter, Instructor=Oktató),
melyek a diagramm független entitásait jelölik. A föléírt nevek
az entitások nevei. Az entitást akkor nevezzük függetlennek,
ha a téglalap elválasztó vonala felett beírt attribútum nevet az úgy
nevezett elsődleges kulcsot (mely egyértelműen azonosítja az
entitás valamennyi elemét, azaz valamennyi diákot, valamennyi tantárgyat, stb.)
az entitás nem örökli más entitástól, hanem saját maga birtokolja.
Az elsődleges kulcsok esetünkben: Soc-Sec-No (TB-szám),
Course-Code (Tantárgy-Kód), Semester-No (Szemeszter-Szám), Instructor-ID
(Oktató-Azonosító).
Az elválasztó vonal alatt helyezkednek el az entitások egyéb
attribútumai: Student-Name (Diák-Neve), Student-Address (Diák-Címe);
Course-Name (Tantárgy-Neve), Std-Cred-Hrs (Szbv-Kred-Órsz); Start-Date
(Kezdő-Dátum), End-Date (Bef-Dátum); Instructor-Name (Oktató-Neve),
Instructor-Addr (Oktató-Címe), Degree (Fokozat), Instructor-Type
(Oktató-tipusa).
|
|
5.38 ábra - FA
színtű diagram tantárgy választási témából
|
A következő sorban elhelyezkedő entitásokat legömbölyített
sarkú téglalapok ábrázolják. Ez az úgynevezett függő entitások jelölése.
Az entitásokat akkor nevezzük függő entitásoknak, ha a szülő (előző)
entitás(ok) teljes elsődleges kulcsát egy reláción keresztül
átveszik és beépítik a saját elsődleges kulcsukba. Az ilyen relációt azonosító
relációnak nevezik. Utalni szeretnénk a relációs
adatbázisok ismertetésére, ahol megmagyaráztuk, hogy az elsődleges kulcs
nem csak egyszerű hanem összetett is lehet. Azaz a teljes kulcs alatt az
összetett kulcs valamennyi részét értjük. A szülőtől átvett kulcsot idegen
kulcsnak (Foreign Key) nevezik és az attribútum után írt (FK)
betűkombinációval jelölik a diagramban.
Az Enrollment (Beiratkozás) entitás elsődleges kulcsa négy
átvitt idegen kulcsból áll, melyek közül egy a Soc-Sec_No a Student entitás
teljes elsődleges kulcsa, míg a következő három Course-Code, Semester-No és
Section-No (Csoport szám) a harmadik sorban lévő Class-Section (Osztály-Csoport)
entitás teljes összetett elsődleges kulcsa , azaz az Enrollment
függő entitás. Az entitás nem kulcs jellegű (azaz vonal alatti) attribútumai a
következők: Date-Enrolled (Beiratkozás-Dátuma), Enrollment-Status
(Beiratkozási-Státus), Enrollment-Type (Beiratkozási-Tipus).
Az Offering (Kínálat) entitás összetett elsődleges kulcsát két
idegen kulcs a Course entitás elsődleges kulcsa - Course-Code és a Semester
entitás elsődleges kulcsa - Semester-No alkotják. Mivel az átvitt kulcsok
mindegyike komplett elsődleges kulcs, az Offering entitás függő entitás. A
vonal alatt még egy, nem kulcs jellegű attribútumot az Act-Cred-Hrs
(Akt-Kred-Órk) találunk.
A következő két entitás a Full-time (Fő-állás) és Part-time
(Mellék-állás) különleges, úgy nevezett kategorizáló relációval
származik az Instructor entitásból, egyszerű elsődleges kulcsuk Instructor-ID
pedig megegyezik az eredeti entitás elsődleges kulcsával, ami úgy lehetséges,
hogy a tanárok entitás egyedei megoszlanak a két entitás típus között. A fentiek
szerint tehát ezek az entitások is függő entitások. A reláció teljes, mivel
valamennyi oktató a két kategória egyikébe tartozik. Az egyéb attribútumok
közül a Full-time entitás az Annual-Salary (Éves-Fizetés)-t, a Part-time
entitás pedig a Hourly-Rate (Óra-Díj)-at tartalmazza.
Mielőtt a következő entitásokra rátérnénk ismerjük meg a
specifikált relációk fogalmi és grafikai jellemzőit.
Az IDEF1X a relációs kapcsolat három fő típusát különbözteti
meg:
- a
specifikus összeköttetési relációt, mely
lehet
- azonosító
reláció,
- nem
azonosító reláció, ezen belül
- kötelező
nem azonosító reláció, és
- opcionális
nem azonosító reláció;
- a
kategorizálási relációt, melynek két
lehetséges variánsa a
- teljes
kategorizálási reláció és a
- nem
teljes kategorizálási reláció;
- a
nem specifikus relációt.
|
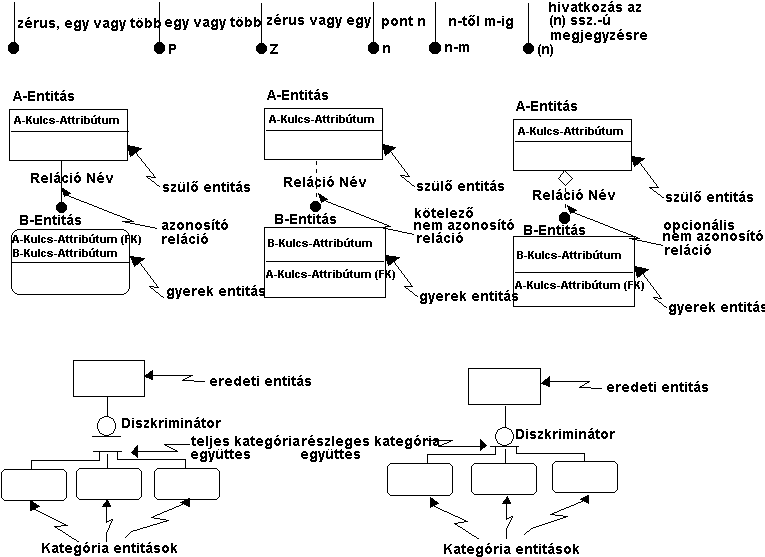
|
5.39 ábra -
relációk grafikai jellemzői
|
Az 5.39 ábrán felvázoltuk a különböző relációk jelölési
módját, a reláció típusok tartalmi jelentését pedig az alábbiakban foglaljuk
össze.
Minden specifikus összeköttetési relációt egy a szülőtől a gyerek felé mutató vonal reprezentál,
melynek a gyermekoldali végén kitöltött pont van. A reláció gyerek oldali
mutatója (kardinalitása) alapértelmezésben (ha nincs semmi a pötty mellé írva)
0, 1 vagy sok (azaz megszokott jelölésünkkel 1:0, 1:1, 1:N). Ne felejtsük el,
hogy az M:N relációkat nem specifikus relációknak hívja a szabvány és a felsőbb
szinteken feloldja specifikus relációkkal.
Az ábra felső sora szerinti jelekkel az alapértelmezési
értékeket finomítani lehet.
Az azonosító relációról már beszéltünk a függő
entitások kapcsán. Ezt csak azzal kell kiegészítenünk, hogy azonosító reláció
esetén a gyerek entitás mindég függő, tehát legömbölyített téglalappal
ábrázolandó, illetve hogy a relációnak nevet is kell adni (ez különben minden
összeköttetési relációra igaz), aminek valamilyen igei kifejezésnek kell lennie
(szemben az entitások és attribútumok nevével, amik főnevek).
A nem azonosító relációk gyerek entitásai nem öröklik
elsődleges kulcsukat a szülő entitástól, ezért a gyerek entitásokat szögletes
téglalap ábrázolja. Ezenkívül még az összeköttetés rajzi megjelenítésére
szaggatott vonalat alkalmaznak. A kötelező nem azonosító reláció azt
jelenti, hogy a gyerek entitás minden egyede a szülő entitás egy-egy
meghatározott egyedéhez kapcsolódik (amint majd példánkból látni fogjuk minden
tankörnek lesz egy konkrét oktatója). Az opcionális nem azonosító relációra
ez a szabály már nem igaz, itt a gyerek entitás egyedei zérus vagy egy egyedhez
csatlakoznak a szülő entitásban. Rajzilag ezt a reláció típust a szülő entitás
alá rajzolt rombusz különbözteti meg a kötelező nem azonosító relációtól.
A kategorizálási reláció
lehetővé teszi, hogy az eredeti entitás (ez felel meg itt az
összeköttetési reláció szülő entitásának) elemeit típusokba csoportosítsuk. A
csoportosítást az eredeti entitás egyik attribútuma alapján végezzük. Ezt az
attribútumot diszkriminátornak hívjuk és a diagrammon az eredeti
entitásból kiinduló vonal alá rajzolt kör mellé írjuk. Ezeknek a relációknak
nincs nevük, ezt pótolja a diszkriminátor. E relációkban a gyerek entitásoknak
megfelelő kategória entitások minden esetben függő entitások és
lekerekített téglalappal ábrázolandók. Teljes kategorizálási reláció
esetén a kategória entitások teljes halmazt alkotnak, azaz az eredeti entitás
minden egyede besorolható valamelyik kategóriába. Nem teljes kategorizálási
reláció esetén lesznek olyan egyedek az eredeti entitásban, melyek
kategóriájának megfelelő kategória entitás hiányzik. A kategorizálási reláció
grafikus vonatkozásai jól szemlélhetők az 5.39 ábrán.
A nem specifikus relációt amint
már említettük a KB és FA szinteken specifikus azaz 1:N
relációkká kell alakítani. Hogy ez miként történik újabb entitások bevonásával
már bemutattuk a hálós adat modellről szóló pontban
(igaz fordított értelemben).
Ezután a kis kitérő után visszatérhetünk
példánk elemzésére.
A következő két entitás a Grade (Fokozat) és
Audit (Vendég-Hallgató) teljes kategorizáló relációval származik
az Enrollment (Beiskolázás) entitásból, összetett elsődleges kulcsuk pedig
megegyezik az eredeti entitás elsődleges kulcsával, ami úgy lehetséges, hogy a
beiskolázott entitás egyedek megoszlanak a két entitás típus között. A fentiek
szerint tehát ezek az entitások is függő entitások. A reláció teljes, mivel
valamennyi hallgató a két kategória egyikébe jelentkezhet. A kategorizálás az
Enrollment-Type (Beiskolázási-Tipus) nevű diszkriminátor attribútum
segítségével történik.
A függő Attendance (Jelenlét) nevű entitás
azonosító relációval kerül az Enrollment (Beiskolázás) entitásból levezetésre.
A gyerek entitás összetett kulcsa a szülő összetett kulcsából és a Class-Date
(Foglalkozás-Dátuma) attribútumból áll. A nem kulcs jellegű attribútumok közül
(a vonal alatt) az Attendance-Status (Jelenléti-Státus) szerepel az entitásban.
A Class-Section (Osztály-Csoport) függő
entitás összetett kulcsának első részét az Offering (Kinálat) entitástól kapta,
melyhez még hozzárakja a saját Section-No (Csoport-Szám) kulcsrészét. Arról már
szóltunk, hogy ez az entitás maga is szülő az Enrollment (Beiskolázás) entitás
vonatkozásában. E mellett még kötelező nem azonosító reláció kapcsolja az
Instructor (Oktató) entitáshoz, melyből kiderül, hogy melyik oktató melyik tanulókört
vezeti. Vonal alatti attribútuma az Instructor-ID (Oktató-Azonosító) szintén
idegen kulcs (FK), de ez nem része az entitás összetett elsődleges kulcsának. A
Class-Section (Osztály-Csoport) nem csak az Enrollment, de a Class-Text
(Osztály-Tankönyv) függő entitás felé is szülőként szerepel.
A Class-Text (Osztály-Tankönyv) függő entitás
egyik szülőjét már említettük, másik szülője a Textbook (Tankönyv) független
entitás. Ez utóbbi a rendelkezésre álló tankönyvek tárolására szolgál,
elsődleges kulcsa a Textbook-No (Tankönyv-Szám), vonal alatti attribútumai a
Textbook-Name (Tankönyv-Címe) és a Pub-Co-Name (Kiadó-Neve).
Bár a felvázolt példa kapcsán több
részletkérdésre nem tértünk ki, reméljük hogy ismertetésünk megkönnyíti
valamely IDEF1X-et értelmezni képes CASE szoftver használatát.
A Közös Objektum Kérés Közvetítő (CORBA) architektúra új,
hálózaton elosztott különféle (heterogén) objektumok közös felhasználását
lehetővé tevő infrastruktúra, mely specifikációt az Objektum Kezelő Csoport
(Object Management Group vagy OMG)
dolgozta ki.
A rendszer architektúrája két fő részre osztható: az objektum
modellre és a referencia modellre. Az objektum modell azt határozza meg, hogy a
hálózaton szétosztott objektumok milyen módon írhatók le. A referencia modell
az objektumok egymásra hatását jellemzi.
Az objektum
modell elemei különálló, egyedien azonosított entitások, melyek szolgáltatásait
csak jól meghatározott interfészeken keresztül lehet elérni. Az objektumok
szolgáltatásait igénylő kliensek számára az egyes objektumok implementációja és
helye rejtve van.
A CORBA számos közös hálózati programozási feladatot
automatizál, többek közt az objektum regisztrálást, elhelyezést, aktiválást, a
kérések lebontását, illesztését és a hiba kezelést, a paraméterek rendezését, a
műveletek szervezését.
|
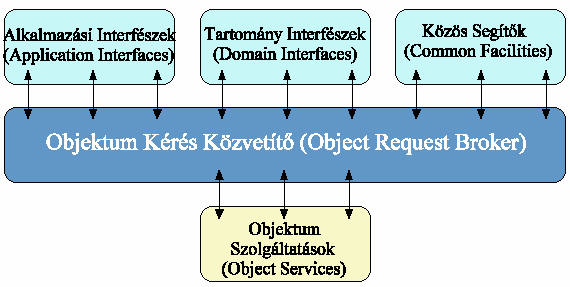
|
5.40 ábra - a
CORBA funkcionális blokk-vázlata
|
Az 5.40 ábra bemutatja a CORBA funkcionális blokk-vázlatát. Az
ORB feladata főként a kliensek és objektumok közötti kommunikáció
lebonyolítása. Az ORB az alábbi négy objektum interfész kategórián keresztül
használható.
Az Objektum Szolgáltatásokat alkalmazási
területtől függetlenül számos osztott objektumokkal dolgozó program használja.
Pld. az olyan szolgáltatás, mely lehetővé teszi más elérhető szolgáltatások
feltárását szinte mindég hasznos függetlenül a felhasználási területtől.
Példaként megemlítjük a Név Szolgáltatást,
mely segítségével a felhasználó az objektumokat nevük alapján érheti el vagy a Kereskedelmi
Szolgáltatást mely segítségével a kliensek objektumokat kereshetnek azok
tulajdonságai alapján. Létezik még specifikáció az élet ciklus kezelésre,
biztonságra, tranzakciókra, esemény jelzésre, stb.
A Közös Segítők is az Objektum
Szolgáltatásokhoz hasonlóan szintén horizontálisan irányított interfészek azzal
az eltéréssel, hogy kizárólag végfelhasználói alkalmazásokra irányulnak.
Példaként említjük az Osztott Dokumentum
Komponens Segítőt (Distributed Document Component Facility (DDCF)), mely
az OpenDoc specifikáción alapul és lehetővé teszi például hogy a
jelentésbe különböző helyekről táblázatokat illesszenek.
A Tartomány Interfészek hasonló
szerepet játszanak mint az Objektum Szolgáltatások és a Közös Segítők azzal a
különbséggel, hogy egy speciális alkalmazási tartományra irányulnak. Az első
specifikációt a gyáripar számára adták ki, készülőben a távközlési, orvosi és
pénzügyi tartományok specifikációi. Itt kell megemlítenünk, hogy a
térinformatikai tartomány specifikációja is készül, részben ezt szolgálják az
OpenGIS törekvések.
Az Alkalmazási Interfészek egy speciális
alkalmazásra készülnek és ezért nem szabványosítottak, ha azonban egy alkalmazás
igen népszerűvé válik, úgy az OMG elhatározhatja, hogy elkészíti a
specifikációit és ezzel átkerül a szabványos tartományi interfészek közé.
A CORBA főbb komponensei a következők:
Az 5.41 ábra bemutatja a CORBA ORB (sötétkék blokk az 5.40
ábrán) főbb komponenseinek architektúráját.
|
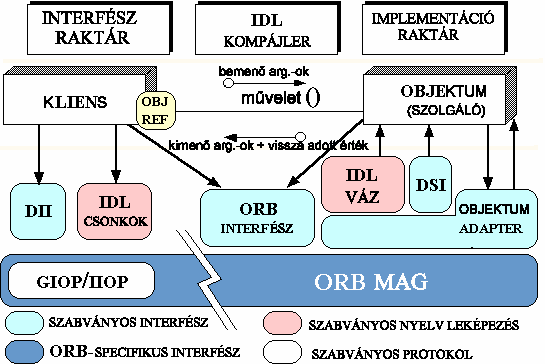
|
5.41 ábra - a
CORBA ORB főbb komponensei
|
Amint már említettük a CORBA heterogén hálózati objektumok
átlátszó elérését teszi lehetővé a kliens számára. Ahhoz, hogy ez
megtörténhessen az objektumokat implementálni kell, ami azoknak a
műveleteknek együttesét jelenti, melyek létrehozzák a CORBA IDL interfészt
(IDL = Interface Definition Language azaz interfész definíciós nyelv). Maga az
implementálás számtalan nyelven, többek közt C, C++, Java, Smalltalk, és Ada
nyelven is íródhat.
Kliensnek
nevezik azt a programot, mely műveletet kezdeményez az objektum implementáción.
A távoli objektum szolgáltatásainak elérése átlátszó kell hogy legyen a
meghívó számára, ideális esetben ez az aktus nem kell hogy különbözzön valamely
helyi objektum módszer hívásától.
Az 5.41 ábra többi eleme ezt az átlátszóságot hivatott
támogatni.
Az ORB Magja vezérli azt a
folyamatot mely átlátszóan kezeli a cél objektum implementációk felé irányuló
kliens kéréseket. Az ORB egyszerűsíti az osztott programozást mentesítve a
klienst a módszer meghívások részleteitől, ezért a kliens kérés úgy tűnik mint
egy helyi eljárás meghívása.
Amikor a kliens egy műveletet kezdeményez az ORB felel azért,
hogy megtalálja az objektum implementációt és transzparensen aktiválja azt
szükség esetén, átadva az objektumnak a megkeresést és továbbítva minden
választ a hívó felé.
Az ORB Interfész Az ORB egy olyan logikai
entitás, mely számtalan módon implementálható, mint például egy vagy több
eljárás vagy egy könyvtár gyűjtemény segítségével. Azért hogy az alkalmazásokat
ne terheljék az implementációs részletek a CORBA specifikáció meghatározza az
absztrakt ORB Interfészt. Az interfész számtalan segítő funkcióval is
rendelkezik - pld. sztringgé alakítja az objektum referenciákat vagy fordítva,
és az alább ismertetendő dinamikus hívás interfészen (DII) keresztül argumentum
listákat készít a megkereséseknek.
Az objektum interfészeket az Interfész Definíciós
Nyelven (Interface Definition Language=IDL) határozza meg a CORBA
specifikáció. Az IDL deklaratív nyelv mely segítségével létrehozott objektum
interfész megmondja, hogy az objektum milyen típusokat és műveleteket támogat.
Mivel az IDL nem programozási nyelv az alkalmazásokat nem
lehet benne megírni, de azért hogy ezek a más nyelven írt alkalmazások
megértsék az IDL interfészeket Nyelvi Leképezéseket (Language Mappings)
alkalmaz a CORBA, azaz lefordítja az IDL interfészeket az alkalmazások nyelvére
(C, C++, Smalltalk, Ada 95, JAVA, stb.).
A CORBA IDL csonkok és vázak a ragasztó szerepét játsszák a kliens alkalmazás illetve a szerver
alkalmazás és az ORB között. A csonkokat, más néven helyettesnek (proxy) is
hívják. Ezek az alkalmazás nyelvére lefordított IDL szerkezetek képviselik az
alkalmazói program számára a kérdéses objektumot, azaz a program a csonkra adja
ki a helyi függvény hívást, melyet a csonk az ORB interfészen keresztül az
objektumba épített vázra továbbít, mely az objektum felé helyi hívásként
jeleníti meg a távoli megkeresést. A fent leírt mechanizmus feltételezi, hogy a
csonkok és vázak a priori információval rendelkezzenek a meghívott
objektumok IDL interfészéről.
A transzformációt a CORBA IDL definíciók és a tárgy program
nyelv között a CORBA IDL Kompájler automatizálja. A kompájler
használata csökkenti az inkonzisztenciák lehetőségét a kliens csonkok és a
szerver vázak között e mellett növeli az automatizált kompájler optimalizálás
lehetőségét.
A Dinamikus Hívási Interfész (Dynamic Invocation
Interface (DII)) lehetővé teszi, hogy a kliens közvetlenül elérje az ORB által
nyújtott megkeresési mechanizmust, ezért a DII olyan általános csonknak
tekinthető, mely független a meghívott objektumok IDL interfészétől, s melyet
közvetlenül az ORB biztosít. Az alkalmazások arra használják a DII-t, hogy
dinamikus kérést adjanak ki az objektumoknak a nélkül, hogy az IDL interfész
specifikus csonkok bekapcsolásra kerülnének. Az IDL csonkok ugyanis csak RPC
(Távoli Eljárás Hívás) típusú kérésekre alkalmasak, míg a DII alkalmas nem
blokkoló késleltetetten szinkronizált (külön művelet az elküldés és a fogadás)
és egy irányú (csak elküldött) hívások kezelésére is.
A Dinamikus Váz Interfész (Dynamic Skeleton
Interface (DSI)) a kliens oldali DII szerver oldali analógja. Lehetővé teszi,
hogy az ORB meghívjon egy olyan objektum implementációt, melynek nincs előzetes
ismerete az implementált objektum típusáról. A megkereső kliens pedig szintén
nem tudja, hogy az objektumnak van e típus specifikus váza, vagy pedig az ORB
dinamikus vázait használja.
Az Objektum Adapterek (Object Adapters)
kapcsolatot alkotnak a CORBA valamely programozási nyelven implementált
objektuma és az ORB között. Tulajdonképpen arról van szó, hogy az objektum
adapteren keresztül a hívó olyan objektumokat is meg tud keresni, melyek valódi
interfészét nem ismeri.
A Belső ORB Protokollok a hálózaton különböző
helyeken elhelyezkedő ORB-k együttdolgozását hivatottak biztosítani. A GIOP
(General Inter-ORB Protocol) rögzíti az átviteli szintakszist és a szabványos
üzenet formátumokat bármely összeköttetés orientált átvitel esetén. Az IIOP (Internet
Inter-ORB Protocol) azt specifikálja, hogy miként épül fel a GIOP a TCP/IP
Internetes hálózati átviteli protokoll felhasználásával.
Az objektum orientált programozás általánossá
válásával szükség volt olyan szabványos grafikus nyelvre, melyet az objektum
orientált elvek alapján fejlesztettek ki. Ez a nyelv az ULM.
A nyelv kifejlesztésére 1996-ban 12 nagy
szoftvergyártó konzorciumot alapított. A specifikáció elkészítése nem váratott
sokáig magára. 1997-ben az OMG (Object Management Group) szabványosította az
UML 1.1 verzióját, jelenleg (1999-ben) elkészült az UML 1.3 verzió tervezete,
melyet még az idén kívánnak elfogadni. A nyelv kidolgozásában döntő szerepet
játszott a Rational Software cég
három munkatársa Grady Booch, Jim Rumbaugh és Ivar Jacobson. Az
említett Rational Software honlapján található az UML-hez kapcsolódó irodalom
leggazdagabb tárháza. Megemlítjük még hogy a cég Rational Rose nevű
szoftvere talán a legjobb UML alapú CASE szoftver, mely shareware
verziói az említett honlapról letölthetők.
Az UML objektum orientált elveken alapuló
grafikus modellező nyelv, melyet elsősorban bonyolult szoftver rendszerek
tervezésére és dokumentálására használhatunk, de tulajdonképpen minden
bonyolult üzleti, szolgáltatási, termelési folyamat modellezésére alkalmas. A
nyelv azonban csak eszköz a modellezéshez, de nem módszer, azaz azok számára
hasznos, akik ismerik az objektum orientált rendszerek tervezési, modellezési
eljárásait.
Maga a specifikáció 6 fő részből áll: UML összefoglaló,
Tartalmi szabályok (szemantika), Jelölési szabályok, UML kiterjesztések, UML
CORBA Interfész definíció, A korlátozásokat leíró nyelv (OCL) specifikációja.
Az UML a modellezés tárgyát képező jelenséget
a következő öt nézeten keresztül közelíti meg:
-
Használati nézet (use-case view)
-
Logikai nézet (logical view)
-
Komponens nézet (component view)
-
Versengési nézet (concurrency view), ez a nézet a Rational Rose szoftverben nem szerepel, ezért
ismertetésétől eltekintünk
-
Megvalósítási nézet (deployment view).
|
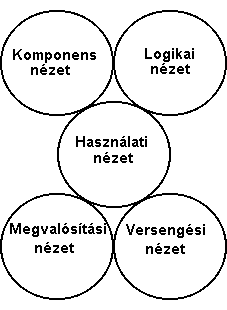
|
5.42 ábra - az
UML nézetek
|
|
Az 5.42 ábrán szemléltetjük a nézetek logikai
elhelyezkedését.
A nézetek ugyanannak a jelenségnek különböző megközelítései,
következésképpen a nézeteket leíró diagrammokban szereplő
fogalmak több nézet különböző diagramjában is konzisztensen kell hogy
megjelenjenek.
A használati nézet a rendszer
funkcionalitását hivatott modellezni. A nézetet 'szereplők' és 'felhasználások'
alkotják. Ez a nézet hivatott biztosítani, hogy a rendszer azokat a
feladatokat oldja meg, melyeket a felhasználók megkívánnak tőle.
|
Lényeges megemlíteni, hogy ez a nézet kívülről szemléli a
rendszert, azaz a rendszer belső építkezése nem e nézet struktúráját, hanem
funkcionalitását hivatott megvalósítani.
Az 5.43 ábra eredetijét (a kék magyarázó szöveg és nyilak
kivételével) a Ratianal Rose 98 kiértékelési (30 napig használható) verziójával
készítettem egy egyetemi nyilvántartási rendszer használati modelljeként.
Mielőtt a magyarázatokat megkezdeném elmondom, hogy a szereplőknek és
felhasználásoknak igyekeztem ékezet nélküli magyar neveket adni, ezt
természetesen nem tehettem meg ott, ahol a szoftver adta meg a szabványos angol
nyelvű szöveget.
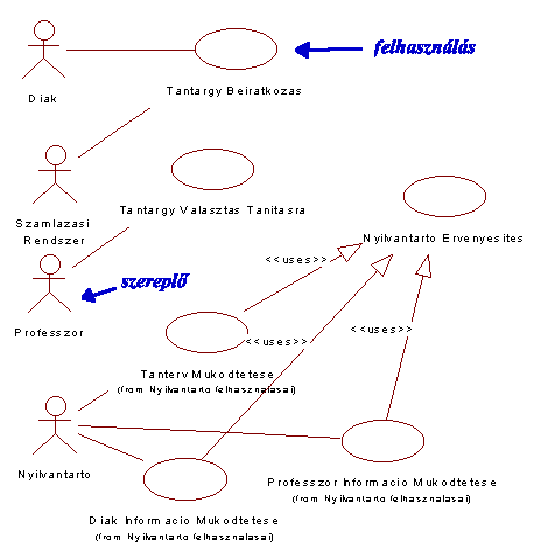
A használati nézetet három diagram típus modellezi, ezek közül
az első az 5.43 ábrán látható felhasználási (use-case) diagram. A
diagram elemei a szereplő (Actor) pálcika emberrel jelölve, a felhasználás
(Use-Case) a jele ellipszis, az egyszerű vonallal jelölt kommunikációs
kapcsolatok és két üres nyíllal jelölt <<uses>> vagy
<<extends>> sztereotípiákkal címkézett generalizáló kapcsolat
típus.
Strukturális szempontból még érdekes megjegyezni, hogy
valamely szereplő különböző felhasználásait csomagba (package)
lehet szervezni, ez történt meg esetünkben a Nyilvantarto Felhasznalasai-val.
A példa gondolati tartalma talán nem igényel különösebb
magyarázatot (gondoljunk a Neptunra).
|
|
5.43 ábra - UML
use case diagram
|
|
|
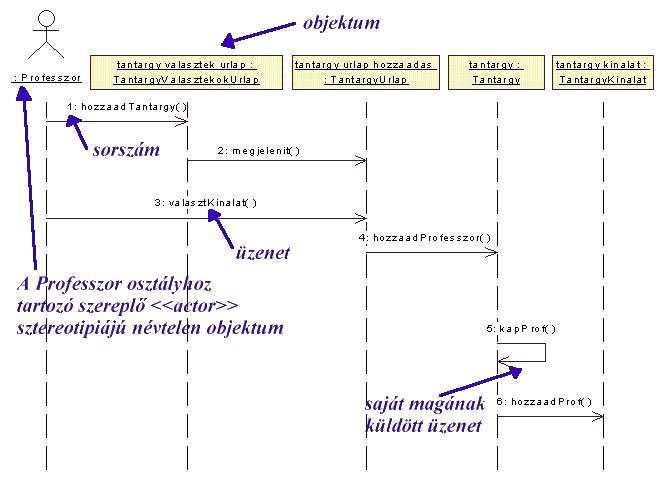
A második diagram típus a folyamat diagram (Sequence
Diagram) felhasználásonként készíthető, és a felhasználás
megvalósításának folyamatában lejátszódó eseményeket szemlélteti.
A folyamat diagramok szereplőket, objektumokat
és üzenetekettartalmaznak. A szereplő jelölése hasonló a
felhasználói diagramhoz, a név megírás azonban már arra utal, hogy a professzor
szereplő tulajdonképpen osztályt reprezentál. Az objektumok jelölésére
szolgálnak a sárga téglalapok, melyekben az objektum neve után megtaláljuk
annak az osztálynak a nevét is, melyhez az objektum tartozik. Az üzeneteket a
küldő (kliens) és a fogadó közötti nyíl reprezentálja kiegészítve az üzenet
sorszámával és nevével. A sorszám ebben a diagram típusban el is volna
hagyható, mivel a diagram függőleges koordinátája egyben az időt reprezentálja
(azaz ami lejjebb van az később következik be). Az objektumok önmaguknak is
küldhetnek üzenetet, ezeket az üzeneteket reflexív üzenetnek hívják, jelölése a
visszahajló nyíl (az 5: üzenet az 5.44 ábrán). A konkrét példa esetében a
folyamat diagram azt reprezentálja, hogy milyen végrehajtási sorrendben jelenik
meg a professzor szereplő félévre vonatkozó tantárgyjavaslata a hallgatók
számára felkínált tantárgy kínálatban.
|
|
|
|
5.44 ábra - UML
sequence diagram
|
|
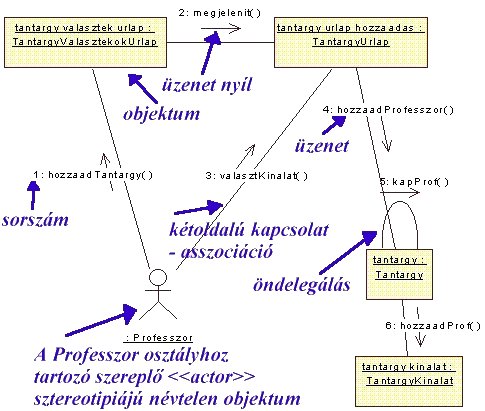
Míg a folyamat diagram a felhasználásban szereplő függvény
hívások (üzenetek) egymásutániságát domborítja ki, addig a felhasználási nézet
harmadik diagram típusa az együttműködési diagram (Collaboration
Diagram) a felhasználásban résztvevő objektumok közötti kapcsolatokra helyezi a
hangsúlyt.
Az együttműködési diagram a Rational Rose
szoftverben a folyamat diagramból automatikusan állítható elő, ami azt jelenti,
hogy nem használ fel új információt, hanem a rendelkezésre álló modell
ismereteket más formában mutatja be.
Új dolgot nem igen tartalmaz ez a diagram típus, legfeljebb
arra érdemes figyelni, hogy az objektumok közötti kapcsolatok illetve a
kapcsolatokat felhasználó üzenetek külön jelölésként jelentkeznek.
|
|
5.45 ábra - UML
collaboration diagram
|
|
|
Mind a használati nézetben, mind a továbbiakban ismertetendő
logikai nézetben lehetőség van úgy nevezett csomagok (package) létrehozására. A
csomagok lehetővé teszik, hogy a valamilyen szempontból összetartozó
felhasználásokból illetve osztályokból csomagokat hozzunk létre s ily módon
egyszerűsítsük a diagrammok megrajzolását. Ebben az esetben ugyanis külön lehet
választani a csomagok közötti kapcsolatok modellezését a csomagon belüli
kapcsolatok modellezésétől.
A logikai nézet, ha szabad így fogalmazni, az
UML fő nézete. Tulajdonképpen két fő diagram típusa van: az osztály
diagramok (Class Diagram) és az állapot átmeneti diagramok
(State Transition Diagram). Az osztály diagramok a rendszer statikus állapotát
modellezik, míg az állapot diagramok a rendszer dinamikus sajátosságait
mutatják be.
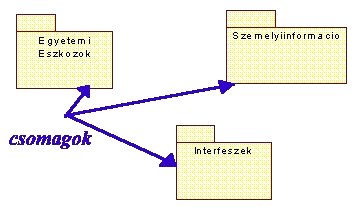
Mielőtt az osztály diagramok részleteire rátérnénk nézzük meg
a tantárgy választási rendszerünk példáján a logikai nézet csomagokra bontását
(5.46 ábra).
|
Amint látjuk a rendszert három csomagra
bontottuk, melyek belső kapcsolatait az osztály diagramokon modellezhetjük.
Megjegyezzük, hogy egy-egy csomag osztálydiagramja tartalmazhat más csomaghoz
tartozó objektumokat is, de ebben az esetben az objektumok csomag-tartozása
az ábrán feltüntetésre kerül.
|
|
|
5.46 ábra -
logikai nézet csomagokra bontása
|
|
Az 5.48 ábrán bemutatjuk az Egyetemi Eszkozok csomag
osztálydiagramját, mely segítségével meg fogjuk ismerni az osztály diagramok
tartalmára és jelölésrendszerére vonatkozó legfontosabb tudnivalókat.
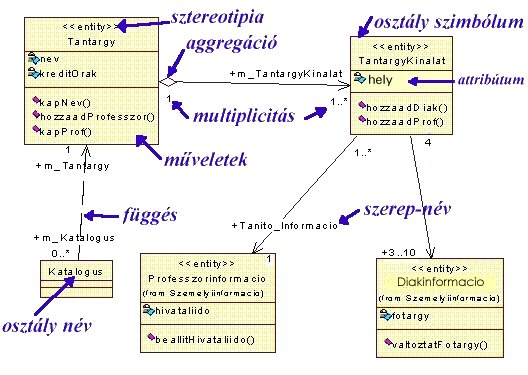
Az osztálydiagramok legfontosabb alkotói az osztályok. Népszerűen
szólva, az osztályok hasonló tulajdonságú objektumok közös tulajdonságait
reprezentáló képződmények. Az osztályok jelölésére három rekeszre osztott
téglalapot használ az UML, ahol az első rész tartalmazza az osztály nevét, a
második rekeszben helyezkednek el az osztály attribútumai a harmadik rekesz
pedig az osztályra értelmezett műveleteket foglalja magába. A jelölési rendszer
lehetővé teszi, hogy a név rekeszen kívüli rekeszek, ha nincs rájuk szükség, ne
legyenek ábrázolva. A név felett francia idézőjelben szerepelhet az osztály
sztereotípiája (a nyelvben előre definiált használati aspektusa), ha ilyen van.
|
Az osztályokra vonatkozóan, a már említett sztereotípián
kívül ábrázolhatjuk még az osztály láthatóságát (más
csomagokból illetve programokból való elérhetőségét) is, ez azonban az
alapértelmezésű nyilvános (public) mellett csak az export vagy import státus
deklarálását teszi lehetővé. Az első esetben semmit sem írunk az osztály név
alá, a második esetben (impl.), a harmadik esetben (from Valahonnan)
szöveget, ahol a Valahonnan az a csomag ahonnan importáljuk.
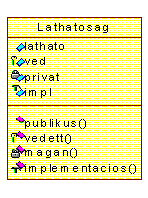
Az 5.47 ábra tanulsága szerint az osztály
attribútumainak láthatóságát a kék téglalap ikon, míg a műveletek
láthatóságát a lila téglalap ikon kulccsal, lakattal vagy kalapáccsal
történő kiegészítése mutatja.
|
|
|
5.47 ábra -
láthatósági ikonok
|
|
Az attribútumok jellemzésére a sztereotípián és néven kívül
szerepeltethetjük még a típusát és kezdőértékét is. Hasonlóképpen a műveleteket
is kiegészíthetjük az argumentum név és a visszaadott típus megadásával. Ha a
diagrammokat nem szabad kézzel rajzoljuk, hanem valamely CASE szoftver
felhasználásával, úgy az említett kiegészítő jellemzők (ha már modelleztük
őket) bármikor megjeleníthetők, ezért az áttekinthetőség érdekében csak akkor
jelenítjük meg őket ha a további modellezési lépések igénylik.
Kiemelkedő fontosságúak az osztályok közötti kapcsolatokat
megjelenítő szimbólumok.
A felhasználási diagram kapcsán már megismert egyszerű
kétirányú kommunikációs kapcsolat vagy asszociáció
(jelölése folyamatos vonal) az osztály diagramban is felhasználható. A
kapcsolatot egy irányúvá tehetjük a megfelelő végén alkalmazott egyszerű
nyíllal. Az asszociációnak nevet is adhatunk vagy - ahogy ezt példánk esetében
tettük - a megfelelő végeihez úgy nevezett szerep neveket (role
name) rendelhetünk annak a szerepnek megfelelően amit a kérdéses végződés a
konkrét modellben játszik.
|
|
|
|
5.48 ábra - UML
osztály diagram
|
|
Az ER diagramok kapcsán már megismert multiplicitást is
jelölhetjük a kapcsolatok végén alkalmazott 1, 0..*, 1..*, +m..n számok illetve
intervallumok megadásával. Érdemes megemlíteni, hogy a két számmal megadott
intervallum szerep névhez kapcsolódik, ezért előtte a + jelet is ki kell írni.
Az 5.48 ábrán még két más jellegű kapcsolat típussal is
találkozunk.
A függést egyszerű nyílban végződő szaggatott
vonal jelöli, ahol a nyíl a független osztályra mutat.
Példánkban az összes tantárgyat tartalmazó Tantargy osztály a független, a
Katalogus osztály pedig, mely információkat tartalmaz a kérdéses félévben
meghirdetett tárgyakról függő, mivel nem hirdethető meg olyan tárgy, amely nem
szerepel a Tantargy-ban.
Az aggregáció (összegzés) jele egy folytonos vonal az egyik végén egy üres
rombusszal. A rombusz az egészet jelentő osztály mellett van, következésképpen a vonal másik vége a részt jelölő osztályhoz
csatlakozik.
Példánkban a Tantargy osztály valamennyi lehetséges tantárgyat
tartalmazza, melynek része a kérdéses szemeszterre meghirdetett
tárgyakat tartalmazó TantargyKinalat osztály. Létezik az aggregációnak egy
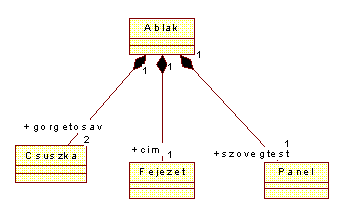
szigorúbb formája is amit kompozíciónak hívnak. Lényege, hogy a
részeket az egész egyidejűleg birtokolja. Jelölése a kitöltött rombusz. Erre
szolgáló példákkal találkozunk majd az OpenGis adatmodell ismertetésénél is,
egyelőre, a tantárgy választási példánktól függetlenül, azt mutatjuk be
az 5.49 ábrán, hogy miként alkotják az ablakot két görgetősáv egy cím és egy
szövegtest szerep nevű objektum.
|
|
5.49 ábra - példa
a kompozícióra
|
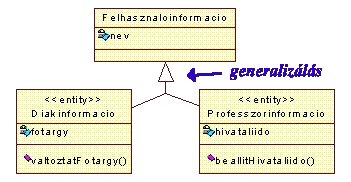
Az 5.50 ábrán bemutattuk a Szemelyiinformacio csomag osztály
diagramját. E diagram segítségével megismerhetjük az utolsó, negyedik kapcsolat
típust a generalizáló kapcsolat típust, mely az objektum orientált
fogalomkörben oly fontos öröklődés modellezésére szolgál.
|
A generalizáló kapcsolat kitöltetlen zárt nyila az
általánosabb szülő osztály felé mutat a leszármazott osztályok irányából. A
leszármazott osztályok öröklik a szülő osztály tulajdonságait, de e mellett
még rendelkeznek egyedi tulajdonságokkal is.
|
|
|
5.50 ábra -
generalizáló kapcsolat
|
|
A logikai nézet másik diagram típusa az állapot diagram.
Ez a diagram azt modellezi, hogy milyen állapot átmeneteken megy keresztül a
vizsgált osztály a feladat indítása és zárása között. Míg az osztály diagram a
feladat statikus szerkezetét dokumentálja, addig az állapot diagram a feladat
dinamikáját szemlélteti.
Tárgy választási példánknál maradva szerkesszük meg az
EgyetemiEszkozok csomag TantargyKinalat osztályának állapot diagramját (5.51
ábra).
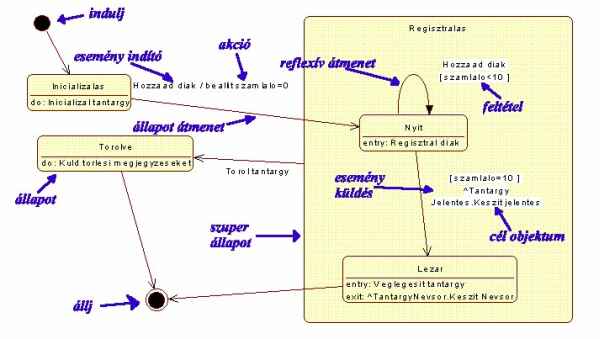
Az állapot diagram kezdő illetve vég állapotát az indulj
és állj ikonok jelölik: az indulj ikon teli fekete kör, az állj ikon a
tömött fekete kört még körülveszi egy üres koncentrikus körrel. Minden állapot
diagramnak egy indulj és egy vagy több állj állapota van.
A következő új szimbólum a közbenső állapotokat reprezentáló
legömbölyített sarkú téglalap. Az állapot szimbólumot egy vízszintes vonal
ketté vágja. A felső részben foglal helyet az állapot neve, az alsó részben
pedig az általa végrehajtott akció. Annak a függvényében, hogy az akció mikor
hajtódik végre 'entry' = belépés, 'exit' = kilépés és 'do' = belépéstől
kilépésig jelző valamelyike előzi meg az akció megnevezését.
|
|
5.51 ábra - UML
állapot diagram
|
|
|
Maga a végrehajtandó cselekmény háromféle lehet. Vagy tulajdonképpeni akció (művelet
végrehajtás), vagy esemény (üzenet) küldés attribútummal vagy attribútum nélkül. Az utóbbi két esetben a fogadó objektumot is meg kell nevezni. Maga
az esemény ^ jellel kezdődik és pont választja el a fogadó objektum nevétől. Ha
az esemény attribútumokat is tartalmaz azok zárójelben követik az esemény
nevét.
Az állapot átmeneteket nyíllal végződő vonalak jelölik.
Tulajdonképpen ezek az átmenetek is rendelkezhetnek azokkal a jellemzőkkel
(akciók, események) mint az állapotok csak az a különbég, hogy átmenet esetén
nem lehet megadni az akció idejét, illetve hogy az átmeneteknél feltételeket is
lehet megadni az akció végrehajtásához. A feltételek szögletes zárójelben
jelennek meg a rajzon. A példánkon látható Nyit állapotot reflexív
átmenet kapcsolja önmagához, azaz az állapot mindaddig visszacsatol a
belépésre és regisztrálja a diákokat amíg a regisztrált diákok száma el nem éri
a 10-et.
Az ábra jobboldalán található Nyit és Lezár állapotokat
Regisztrálás néven összevont
(szuper) állapottá foglaltuk össze. Az ilyen összefoglalás
a bonyolult állapot diagrammok egyszerűbb áttekintését célozza.
A komponens
nézet a logikai nézet
elemeit program modulokra képezi le. A szoftver szervezés komponens
diagrammok segítségével valósul meg. E diagramok információval
szolgálnak a rendszer végrehajtó (exe) fájljairól és könyvtárairól (dll
fájlok).
|
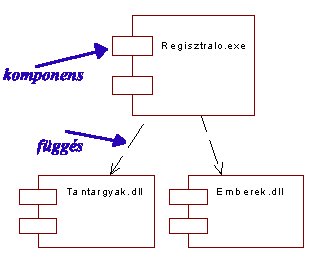
Az 5.52 ábrán a komponens nézetben létrehozott Regisztralas
csomag komponens diagramját rajzoltuk meg. Ahhoz hogy a komponens nézet és a
logikai nézet közötti összhangot megteremtsük meg kell feleltetnünk a logikai
nézet csomagjait a komponens nézet csomagjának. Esetünkben úgy döntöttünk,
hogy az 5.46 ábra mindhárom logikai nézetbeli csomagját a komponens nézet
egyedüli, Regisztralas nevű csomagja képezi le.
|
|
|
5.52 ábra - UML
komponens diagram
|
|
|

|
5.53 ábra - szoftverkomponensek
ossztályokhoz rendelése
|
|
Ezután létre kell hoznunk a Regisztralas csomag
komponenseit: a Regisztralo.exe, Tantargyak.dll és Emberek.dll program
modulokat, majd az 5.53 ábra szerint hozzá kell rendelnünk a logikai nézet
megfelelő osztályaihoz a realizálásukra hivatott szoftver komponenseket. A
hozzárendelést a Rational Rose program tallózó részében végeztük a szokásos
'ráhúzásos' technikával.
|
Az utolsó lépésben megrajzoljuk a diagramban a függőségeket,
kézenfekvő, hogy a végrehajtó modul (Regisztralo.exe) függ a dinamikusan
kapcsolt könyvtáraktól (dll), míg ez utóbbiak függetlenek az exe programtól.
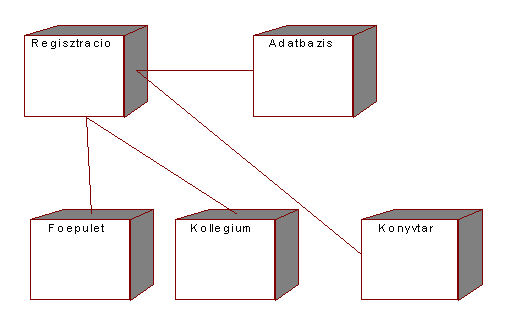
A megvalósítási nézet a futás ideji feldolgozó
csomópont architektúrát vizsgálja a kapcsolódó komponensekkel, folyamatokkal és
objektumokkal. A nézetnek egy diagramja van - a megvalósítási diagram. A
diagram kétféle csomópont típust és összeköttetéseket tartalmazhat. A csomópont
típus vagy feldolgozó kapacitással rendelkező processzor, vagy legalább
memóriával rendelkező úgy nevezett eszköz lehet.
Az 5.54 ábrán bemutatott megvalósítási diagram csak processzor
csomópontokat tartalmaz. A diagram típus másik alkotó eleme az összeköttetés,
mely a csomópontok közötti kommunikációt modellezi. Az összeköttetés
jellemzésére használhatunk sztereotípiát is, ilyen lehet az átviteli csatorna
vagy hálózat típusa. Ábránk esetében eltekintettünk a jellemzőktől.
|
|
|
|
5.54 ábra - UML
megvalósítási nézet
|
|
A téma befejezéseként ismét aláhúzzuk, hogy e rövid
összefoglaló semmiképpen sem célozta meg az UML részletes ismertetését,
különösen nem az objektum orientált programozás modellezési technikája
szempontjából. Célunk csak az volt, hogy az UML segítségével definiált térbeli
adatmodellek az összefoglaló segítségével könnyebben legyenek megérthetők.
Megjegyzéseit
E-mail-en várja a szerző: Dr Sárközy Ferenc
